In this article, I’ll share some tips on how to transform your laptop or PC into a powerful AI machine. This allows you to fully utilize AI without restrictions, costs, or external dependencies. You’ll have complete control by setting up any AI model directly on your device.
Installing AI models locally offers several advantages over using online services like ChatGPT or Gemini.
First, you can choose any AI model you prefer. You can install uncensored and unbiased models or select specialized Large Language Models (LLMs) optimized for tasks like coding or writing.
These models are open-source, but don’t underestimate them. Open-source LLMs are advancing rapidly. For instance, Meta recently released LLaMa 3, which benchmarks competitively against Google Gemini Pro 1.5 and Claude 3 Sonnet in the 70B parameter version. The smaller 8B version even outperforms many other open-source LLMs. I’ve tested it, and the results are impressive.
Second, your data and privacy are better protected. All chats, questions, and AI responses are stored locally. No third parties store or use your conversations for training. This makes local AI ideal for handling sensitive or confidential information.
Read Also:
Third, you can use it freely without paying per token or monthly fees. You’re not dependent on external services that may experience downtime, server overloads, or price changes. Local AI runs directly on your device and can even operate offline.
Fourth, you can customize the AI model to suit your specific needs and tasks.
There are many ways to install AI models on your device, but I’ll share the simplest method for beginners, avoiding complex terminal commands or technical hurdles.
First, ensure your laptop or desktop meets the requirements. Higher specs, especially RAM and GPU, are better. More RAM or VRAM allows running larger AI models with higher quantization bits, improving output quality.
An 8GB RAM device can handle smaller, lightweight AI models, but 16GB RAM is preferable for larger models. While a discrete GPU enhances performance, models can still run via RAM.
Once ready, let’s begin.
First, install LM Studio from LMStudio.ai. After installation, open the app.
The Home screen highlights popular AI models like Llama 3 8B Instruct by Meta, which requires 8GB RAM. Google Gemma with 2B parameters is lightweight and suitable for devices with 8GB RAM or less. Other options are also available.
You can search and select any AI model. The search bar provides open-source LLMs from Hugging Face, sorted by likes or downloads for convenience. Read the model’s Readme or click Open Model Card for details.
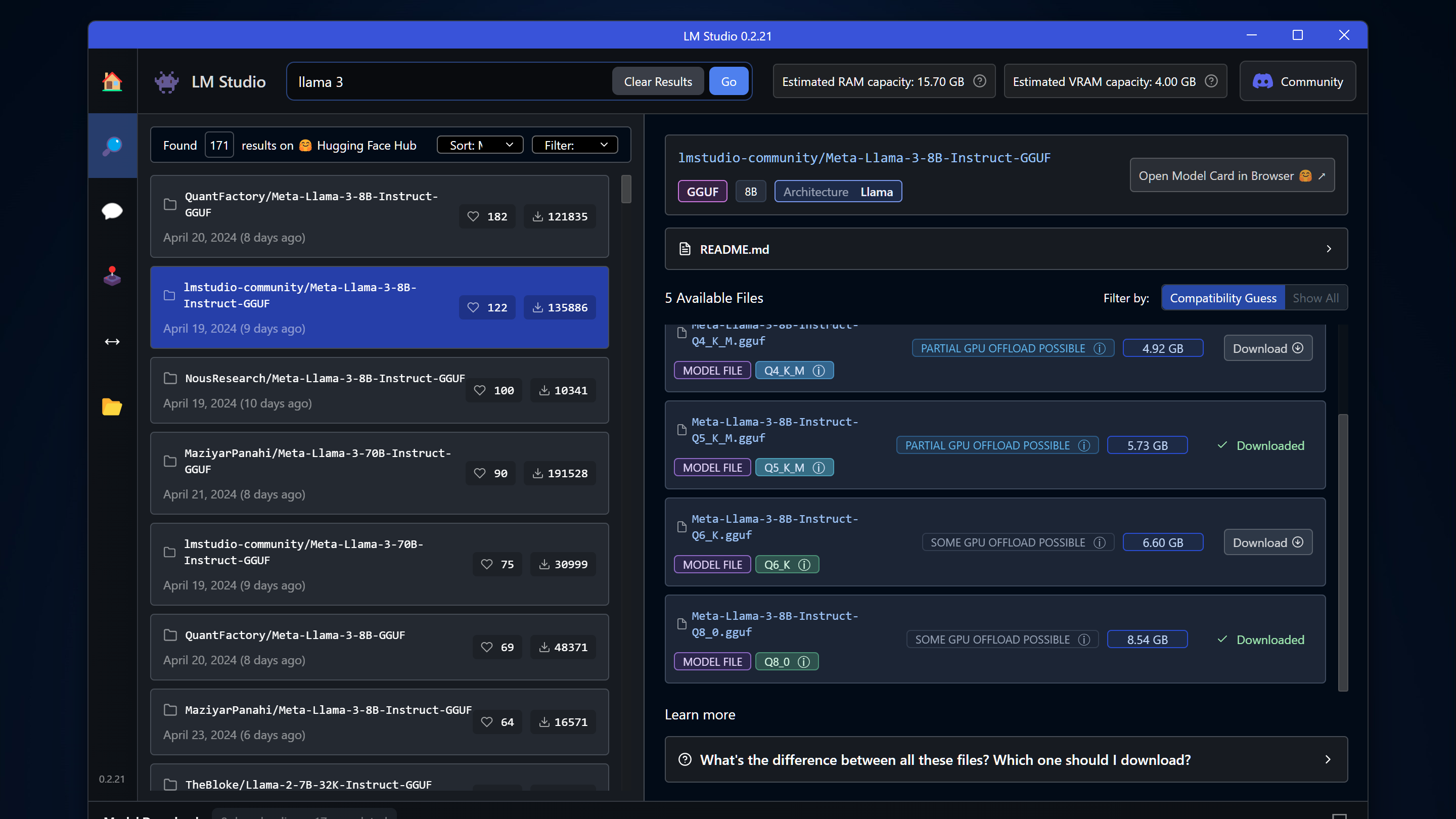
When choosing an AI model, consider the following.
First, parameter size matters. For example, 8B means 8 billion parameters, indicating the number of variables the AI learned during training. Larger parameters generally mean better accuracy, but they also require more resources. For instance, LLaMa 3 with 70B parameters outperforms the 8B version but demands more computational power.
Second, quantization options like Q3, Q4, Q5, Q6, and Q8 compress the model. Lower quantization reduces file size and resource usage but may decrease accuracy. I recommend avoiding models below Q4. Q5 offers a good balance, while Q8 provides the best accuracy if your device can handle it.
Third, check GPU offload details. Full GPU Offload Possible means the model runs entirely on GPU VRAM for optimal performance. Partial GPU Offload offers some performance improvement over RAM-only execution. Likely Too Large for This Machine suggests choosing a smaller model.
Once you’ve selected a model, download it. For example, Dolphin LLaMa 3 is an uncensored version of LLaMa 3, answering questions that other AI services might reject. Mistral is another favorite for brainstorming, while Codellama 7B is optimized for coding.
For lower-spec devices, consider lightweight models like Google’s Gemma 2B (1.5GB for Q4) or Microsoft’s Phi-3 Mini (2.32GB for Q4).
All downloads are displayed below. Once completed, models are stored in the MyModel folder, where you can manage them.
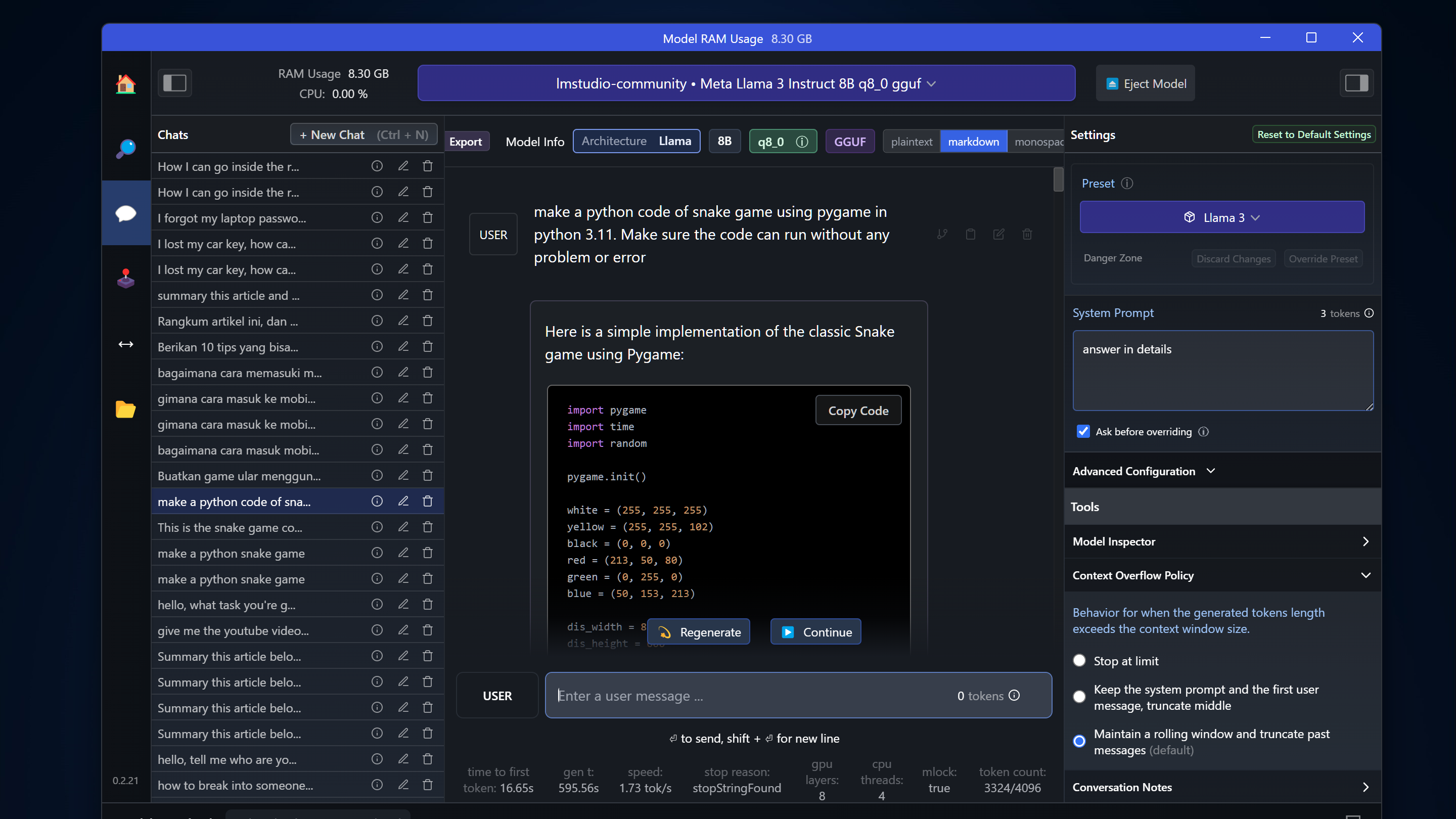
To use the AI, open the chat feature and load your desired model. For example, I used LLaMa 3 for coding assistance. It generated Python code for a snake game without errors and provided detailed explanations for revisions.
On my laptop, LLaMa 3 with 8B parameters and Q8 quantization processes about 3 tokens per second—a decent speed for local AI.
Local AI also handles questions that online services might censor. For instance, Dolphin’s uncensored version provides unbiased answers without ethical restrictions.
You can interact in Indonesian by setting a system prompt, though English remains the AI’s strongest language due to training data.
Compare AI models using the Multi-Model session in Playground, though this is resource-intensive.
While LM Studio is functional, it has limitations. For example, summarizing long articles requires manual copy-pasting. To enhance functionality, use AnythingLLM, available at useanything.com/download.
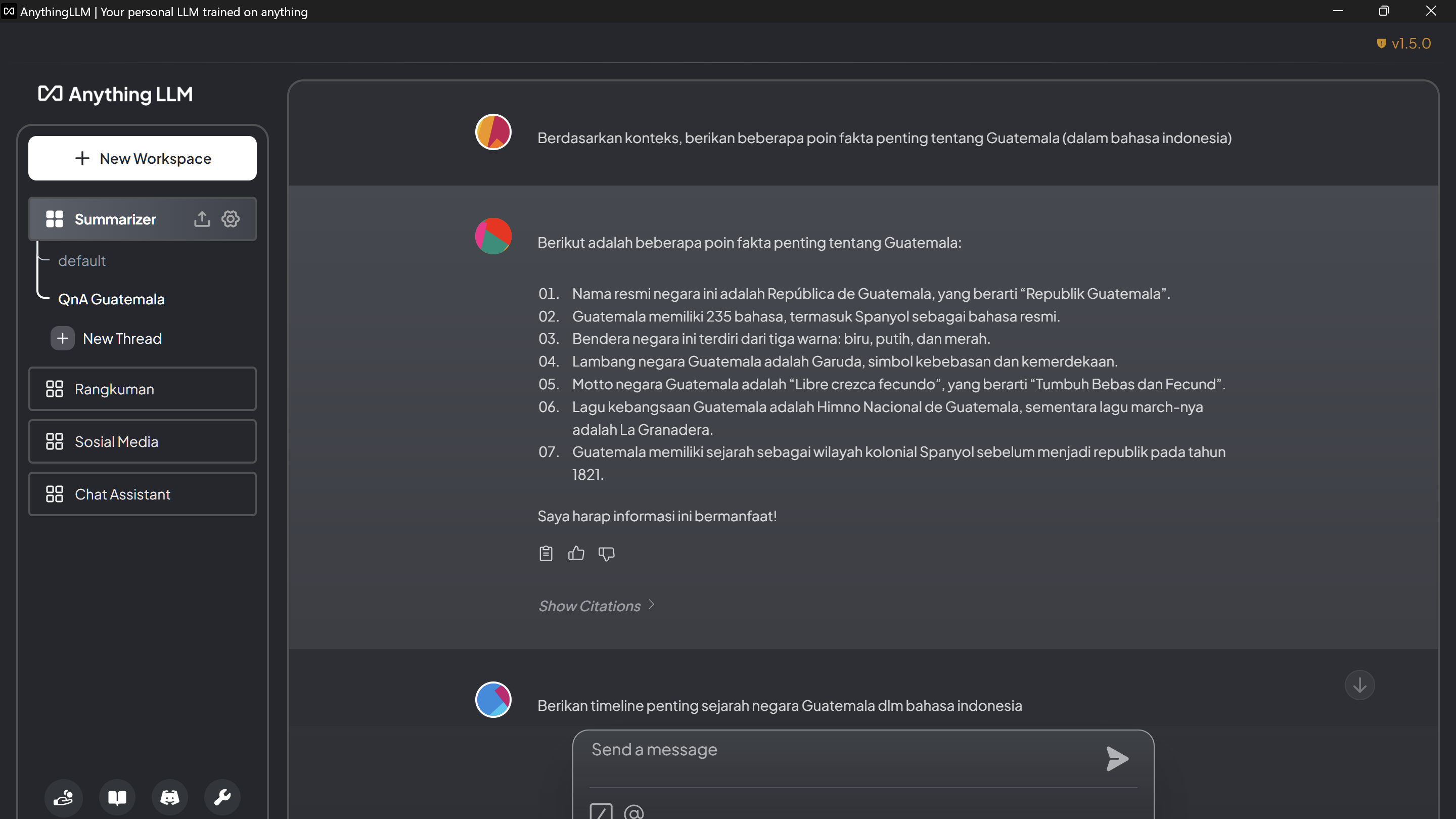
After installation, connect AnythingLLM to LM Studio by starting the local server and copying the base URL. Set the token context to 4096 and proceed with default settings.
Create workspaces to upload files or links. For example, embed a Wikipedia page about Guatemala and ask the AI for key facts or historical timelines.
You can also upload PDFs, CSVs, or audio files to create a knowledge base. The AI uses Retrieval-Augmented Generation (RAG) to reference these documents alongside its training data.
With local AI, you have the freedom to use it for any purpose, with all data stored securely on your device.
That’s all for today. I hope this guide helps you explore and experiment with AI models on your laptop or desktop. If your device can’t handle local AI, consider using APIs like Groq or OpenRouter, which offer affordable token costs for open-source LLMs. However, these rely on external servers, unlike local AI, which operates entirely on your device.
Feel free to ask questions in the comments. See you in the next tutorial!
Kita bisa merangkum artikel web juga tanpa harus copy paste manual. Tinggal fetch aja link artikel nya.
Tapi yang lebih keren lagi, kita bisa memberikan knowledge based ke Workspace ini. Misal kita bisa upload paper PDF tentang dampak sosial media. Tinggal kita upload aja dokumen nya. Dan selain PDF dia juga support file CSV, teks, audio, bahkan support epub juga kalo pengen masukin ebook. Dan setelah diupload tinggal masukkan paper nya ke workspace, dan di pin aja. Habis itu kita bisa tanya-tanya tentang paper nya, poin-poin penting nya apa dsb.
Dan disini kita gak cuman bisa masukin satu dokumen, tapi bisa banyak dokumen dan file sekaligus kedalam workspace, sehingga pas tanya-tanya AI nya, AI bakal mencari dari sumber dokumen yang ada. Kalo di AI ini disebut Retrieval-Augmented Generation atau RAG, dimana kita bisa memasukkan informasi dari dokumen ataupun file sebagai sumber rujukan AI diluar informasi yang dia miliki dari hasil trainingnya, meskipun batasannya adalah panjang konteks yang disupport oleh AI modelnya.
Dan disini temen2 bisa berkreatif aja, mau dipake buat apa local AI nya ini, satu hal yang pasti, karena AI nya ada di laptop kita secara local, kita bebas menggunakannya untuk apapun keperluan kita, dengan data-data yang juga tetap tersimpan local di komputer kita.
Itu yang bisa saya share hari ini. Semoga aja informatif dan bermanfaat buat temen2 yang pengen mengakses dan bereksperimen dengan AI model di laptop atau desktopnya masing-masing. Kalo laptop temen2 specs nya tidak mampu untuk menjalankan local AI yang terkecil sekalipun, masih ada cara alternatif lainnya yaitu menggunakan API kayak dari Groq atau OpenRouter, dimana biaya token untuk open source LLM ini sangat-sangat murah, bahkan di Groq sendiri masih gratis sampai saat ini. Tapi ya beda dengan yang dijalankan lokal yang bener2 bisa kita pake sebebas-bebasnya, AI yang menggunakan API tetap diproses di server mereka, bukan di komputer kita, yang artinya data-data kita juga ditransmisikan kesana, dan ada ketentuan-ketentuan yang berlaku kayak limit request, limit token, atau perubahan-perubahan harga di kemudian hari. Karena memang kita pake resource komputing di server mereka.
Kalo ada pertanyaan silakan sampaikan di kolom komentar, sampai bertemu lagi di tutorial selanjutnya.